Data Responsible AI: Why the Best AI Lives on Your Laptop (And Why That Scares Everyone)

I spend a lot of time thinking about why AI feels simultaneously magical and frustrating. You'll get a response from Claude that makes you think "wow, this thing actually understands me," and five minutes later you're pulling your hair out because it can't remember what you talked about yesterday.
Here's what I've realized (and it may be a no brainer to many): the AI that actually works lives as close to your real data as possible. It's super context aware. And that terrifies both users and companies for completely understandable reasons.
The Context Goldmine Sitting Right Next to You
The most powerful AI interactions I've had weren't with the latest frontier models in the cloud. They were with systems that could see what I was actually working on. Browser tabs, recent emails, the document I'm editing, my calendar... that's where the magic happens.
Human intelligence doesn't operate in isolation. We integrate new information with extensive contextual knowledge, personal history, and situational awareness. The AI systems that feel most intelligent do something similar with user context.
Companies like Vercept and Cluely have figured this out. Their AI deeply understands the relationships between your open applications, recent communications, and current projects. The result feels less like talking to a chatbot and more like collaborating with a colleague who pays attention.
But here's the paradox: all that magical context in your browsing history, email threads, document drafts, internal communications is exactly the information you're most nervous about sharing with "big AI.”
The Trust Paradox That's Holding Everything Back
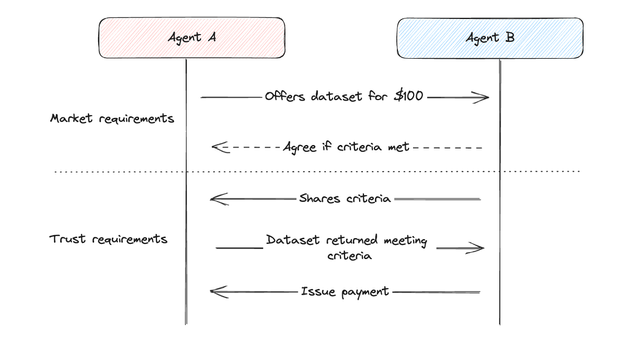
Building transformative, context-aware AI means AI companies must fundamentally respect and protect user trust.
We're seeing a fundamental shift in how AI systems access our data. The surveillance advertising era relied on discrete transactions like clicks or searches to predict purchasing behavior. AI now needs continuous, rich contextual data rather than isolated queries to understand how we communicate, make decisions, and solve problems.
This naturally becomes a sticky topic. The information AI requires today is deeply personal: intellectual property, competitive insights, negotiation tactics, browsing habits, and communication patterns.
Establishing clear guardrails around sensitive data, even for seasoned professionals, is challenging when AI's value relies on comprehensive context. Extending this complexity to everyday consumers intensifies potential unintended exposure.
Why the Trust-Context Flywheel Actually Works
I've noticed something interesting with AI tools. Those I trust with more context consistently provide better results. Better results encourage me to share more, creating a powerful flywheel:
Initial skepticism: Sharing minimal context like one document.
Decent results: Generic but helpful responses.
Cautious expansion: Sharing additional emails or related content.
Notably better results: Responses become relevant and precise.
Growing confidence: Broader sharing of files and workflow details.
Transformational results: AI anticipates needs and provides insightful connections.
This flywheel explains why some AI tools become indispensable. They operate in close proximity to the richest contextual data available. Trust enables deeper sharing, improving results and reinforcing value.
But establishing this trust at scale demands a clear framework around data responsibility.
What Data Responsible AI Actually Means
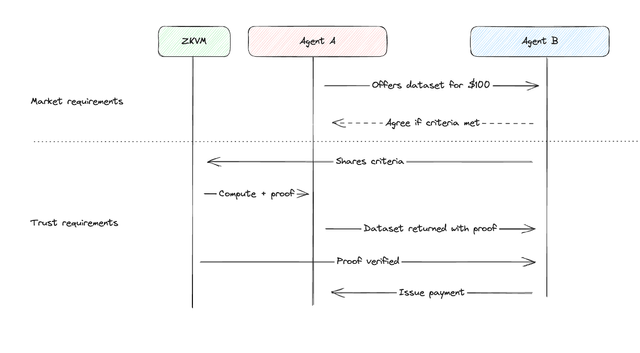
At Sindri, data responsibility starts with infrastructure designed explicitly for protecting user confidentiality and control.
We build systems allowing users to confidently share and respect sensitive context such as emails, browsing patterns, document edits, and workflow sequences. Trusted execution environments ensure that underlying data remains inaccessible even to us.
Data responsible AI enables meaningful context-aware intelligence while fully preserving data ownership and security. Organizations mastering this capability first will earn deeper trust, unlock richer contextual insights, and sustain competitive advantages.
Companies establishing real data responsible AI practices today, not just compliance checklists but actual infrastructure protecting contextual data, will define the next generation of AI. The future belongs to systems capable of leveraging deep contextual insights while maintaining absolute data integrity.
The question isn't whether this shift happens. It's whether your organization will be ready when it does.