Modular Breakthroughs in zkML
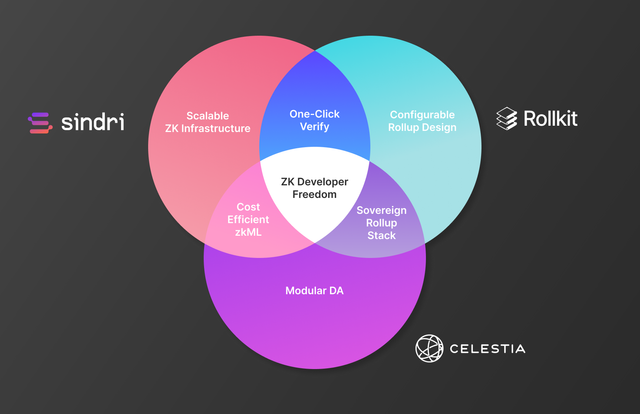
Many consider on-chain zkML to be cost-prohibitive due to computational overhead and data publishing. While that remains up for debate, one thing is clear: Sindri’s powerful proving API + the modular paradigm provides a cost-efficient path towards scaling zkML for anyone looking to enrich blockchain UX.
Together with the teams at Celestia and Rollkit, we wanted to explore how these technologies synergize to unlock new paradigms in zkML applications and smart contract development. By integrating Sindri's efficient proof generation, Celestia's modular data availability, and Rollkit's customizable rollup framework, we deploy zkML in minutes (not days) across scalable block space. Together, we're paving the way for developers to create complex, user-centric experiences enabled by zkML across the modular configuration they deem best.
See the model here, otherwise let’s dive in.
Verifiable ML doesn’t have to be prohibitively expensive for operators or end users.
The core of our findings reveal executing against zkML models with Sindri on Rollkit x Celestia is a) remarkably simple and b) cost-competitive against what’s currently possible on Layer 1 Ethereum. This makes sense given the general purpose nature of Ethereum and breakthroughs in Celestia’s modular blockchain construction + Sindri’s flexible proving API deployable across any EVM ecosystem.
Here’s a snapshot of what we discovered:
-
Verifying our zkML model on Ethereum could cost in the range of $15.00 to $20.00, based on gas prices and the current Ethereum market pricing.
-
In contrast, verifying a zkML model on Rollkit (without accounting for operator expenses) costs just a fraction of a cent per isolated transaction.
Comparing Verification Costs on Ethereum vs. Rollkit x Celestia
Our objective was straightforward: assess the cost of verifying a lightweight zkML model on Ethereum against doing the same on Rollkit x Celestia. EVM compatibility and one-click deployability of Rollkit + Sindri allowed for easy deployment.
Here’s a bit about our setup:
-
We chose a small neural net model for this proof of concept - simple yet effective for demonstration and applicable in a mobile app context. The model we used is trained to identify the origin region of a recipe based on ingredients. It’s a fun twist on the standard ML models and proves that zkML can have engaging, practical applications. You can find out more about that model here.
-
Rollkit served as our execution layer for verification with Celestia DA. Sindri powered proof generation across both the Rollkit and Ethereum environments.
-
Rollkit’s support of the Polaris EVM made deploying Sindri’s verifier contract nearly identical between Ethereum and a local Celestia devnet instance. Readers wishing to replicate our findings can easily do so following Rollkit’s Polaris EVM tutorial and Sindri’s smart contract integration walkthrough. Once deployed, proofs of verifiable inference were submitted via the Sindri API which were then routed to our verifier contracts waiting onchain.
-
Some general assumptions around operator costs, rollup efficiencies, and sequencing logic were made to establish a good baseline for framing the tradeoffs. Lastly, because compute cost using Sindri is consistent in both instances, that cost has not been included in this analysis.
The Results: Demonstrated Cost Efficiency
Our findings are compelling for those seeking to develop zkML with greater customization, powerful infrastructure, and choice of deployment:
-
Verifying our zkML model on Ethereum was approximately
214286 gas, translating to a fee of around $15.00 to $20.00 at average market prices. (Source: YCharts) -
Rollkit transactions, on the other hand, cost about $0.000939 per isolated transaction (assuming a
526 byteblock). This difference in cost underscores the cost efficiency of Rollkit x Celestia for running zkML models, making it an attractive platform for developers and projects keen on leveraging ML in blockchain.
Why This Matters For Builders
Builders are always seeking design optionality and the modular paradigm expands developer choice across that spectrum. In addition to the stark cost difference between deploying your zkML application on Ethereum vs Rollkit, this end-to-end experiment establishes a few points, beyond cost savings, worth emphasizing:
-
First, Sindri's serverless API and portable toolkits enable rapid deployment of zkML circuits across the blockchain environments developers already love to build on. So long as the blockchain is EVM compatible, performing zkML verified inference is streamlined - code once, deploy anywhere.
-
Second, Rollkit x Celestia afforded greater control over our zkML-oriented use cases providing developers a wide range of rollup configurations and optionality paired with cost efficient blockspace on Celestia.
We’re excited to be a part of the Rollkit and Celestia ecosystem. Coupled with Rollkit and Celestia, we turn the dream of flexible zkML deployment into the standard, ushering in an era where ZK utility is globally accessible and recognized as a fundamental developer resource.
We’re eager to continue integrating with teams deploying generational applications built on Celestia and Rollkit as we build out the proving layer. If you’re a team building in the space, let’s talk.