Friendly Introduction to Sindri's API
Zero-Knowledge Programs
Inspired by this thread.
Suppose you have a function that takes in two variables and returns some result:
There are a few consequences of executing the traditional way:
- Anyone wishing to verify
resultwill need both inputsxandy - They will also have to expend compute resources to run
In a trustless setting, you may want to keep some of the variables private or you may want to convince anyone that the result is legitimate without having to rerun the program. Zero-knowledge proofs modify the execution of your program to look more like this:
so that:
- broadcasting
resultandproofreveals nothing abouty - verifying
resultonly requiresproofandx
A major caveat is that takes much longer to execute. Research surrounding the subject of Zero-Knowledge Proofs has proliferated in the last few years. Every work is attempting to optimize at least one of the following:
- The runtime of
- The verification time given
resultandproof - The size of
proof
Proofs
In this section, we present a high level overview of the KZG polynomial commitment scheme in order to explain why generally takes so long. KZG is a popular protocol choice for blockchain developers because the proof size is small and the verification work is minimized. Furthermore, while proving still needs to happen off-chain, verification is enabled on-chain.
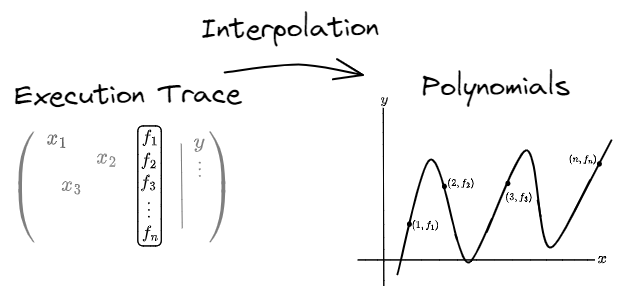
One way to convince someone that you’ve run code is to show your work by publishing the execution trace, i.e. all of the intermediate steps and variable values. You could convince any verifier that you ran the program at the price of giving the verifier full knowledge of private inputs. Additionally, the size of such a proof is unappealing. However, this transformation is still a useful first step towards a zero-knowledge proof.

The diagram above depicts the process of transforming pseudocode into an execution trace, which is sometimes called arithmetization.
We will call the right hand side a circuit: it is a matrix with each entry given by a formula representing some intermediate value of the program.
For a concrete input pair x and y, filling in the actual values of the circuit is known as witness generation.
The next step is going to turn each column of the circuit into a polynomial.
This improvement is not initially obvious.
In the diagram below, we have a vector of length n, which will turn into a polynomial of degree n, and it takes the same amount of data to describe both the vector and the polynomial.
However, we do not intend to publish the entire polynomial for a column.
Rather, we will convince a verifier that we know the global structure of the polynomial and that we can predict how it will behave in any local neighborhood.
The first phase of the polynomial argument, the global structure, functions similarly to a hash. Random hash collisions are unlikely, meaning the hash output is a sufficiently identifying property of a polynomial. Additionally, the hash is irreversible. So, an adversary cannot learn much about the pre-image given only the hash output.

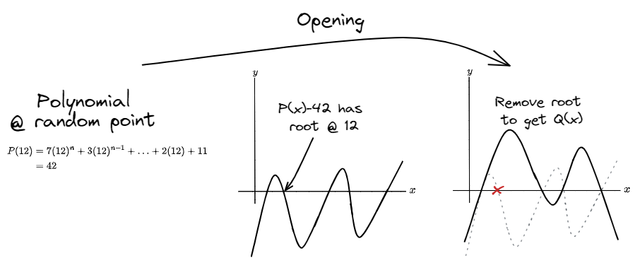
The second phase of the polynomial argument, the local structure, opens up the behavior of the polynomial around any random point (note that the prover does not get to choose this). Consider first the claim: “I have a polynomial and when I plug into it, I get back”. In order to convince a hostile listener that I have full knowledge of this polynomial, I’ll need to supply more information. Like the diagram below indicates, if I know , then will cross the x-axis at . There is a programmatic way (polynomial division) to retrieve a polynomial of degree that crosses the x-axis in all the same places as , except at the root . In short, in my role as the prover I need to supply so that . This is a very convincing argument to the verifier that I know the polynomial . But, to stick to the principles of ZK, I need to withhold both and . We already have a hashed version of , so we’ll supply the hashed version of as well.
The final act is for the verifier to evaluate the proof they have received.
The prover sent along commitments for the two polynomials and in addition to the claim that evaluates to when you plug in .
The verifier is not able to to directly check that the polynomial equation holds but they can check a “hashed” version of this equality, very similar to the way the commitments for and were obtained.
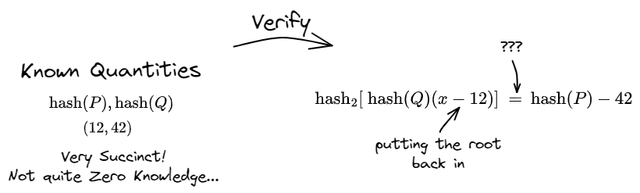
That concludes the steps in a ZK proof. The “not quite zero-knowledge” comment in the diagram above deserves elaboration. If you were to rerun many times and show a different evaluation point of the polynomial each time (the pair), then an adversary gains a little information about your polynomial each time. It would only take them communications from you to completely determine your polynomial and work backwards to get the private value. KZG does not initially qualify as a zero-knowledge protocol, but there are straightforward revisions which grant this property.
The discussion above oversimplified a lot of the “moon math” that makes the final verify equation un-cheat-able. Because of that, the complexity might be unclear. Here are some more specific comments:
- The commitment function, or hash, is not fast. Another name for this operation is ‘multi-scalar multiplication’ or MSM. Each of the coefficients of your polynomial is represented with around 250 bits and the values are elliptic curve points which require around 380 bits to represent. While MSM is O(n/log(n)), n is already large enough for this to be a heavy computational burden. Additionally, KZG requires more calls to MSM than the operation described next, so this is the bottleneck.
- Calculating Q(x) requires polynomial division. Fast fourier transform (FFT) techniques place this computation in O(n*log(n)). In addition to the complexity introduced by large n (the degree of your polynomial), recall that the coefficients are each around 250 bits.
Sindri's API
Hopefully the discussion above has convinced you of the difficulties of producing ZK proofs. If you have your own and want to convert to then there are three major options available to you:
- Perform all the work yourself with your own machines. There are many open source libraries available to you that already provide accelerated proving implementations on certain hardware options. Selecting the implementation that best suits your hardware setup will require a technical deep dive. Additionally, you should not underestimate the work it will take to scale this acceleration beyond your initial prototype and reconfigure the entire stack as needed to stay up to date with a rapidly evolving backdrop.
- Plug into a ZK-VM that will outsource the entire process. As long as you write your program in a way the virtual machine can understand, it will automatically convert it into a circuit and host proofs for you. There may be limitations placed on the development of . For instance, a VM might have trouble with a multi-thread program which is very hard to prove. The biggest perk of competitive VM solutions is that proof acceleration is baked into their product, so that you reap the benefits of an incredibly technical field with zero headaches. However, a crucial consideration with this option is that you have very limited control. The field of ZKP is still evolving and the form takes currently may become obsolete given research advances. You must place a lot of trust in your VM solution to keep pace with those advances while providing stability to your own application.
- Compute the circuit definition and upload to Sindri. Sindri's API offers the middle ground between the previous two options. You’ll need to learn a little bit of the ZK space in order to pick the proving scheme and arithmetization that is right for your use case. Additionally, you’ll have to roll up your sleeves and provide the circuit definition for us. After that, the responsibility of running proofs quickly and reliably falls to Sindri's infrastructure.
Summary
